サイトの検索結果をスクレイピングする
まとめサイトの検索結果がある
例えば病院を探すサイト、病院なびを使う
東京都豊島区で探すと938件表示される
https://byoinnavi.jp/tokyo/toshimaku
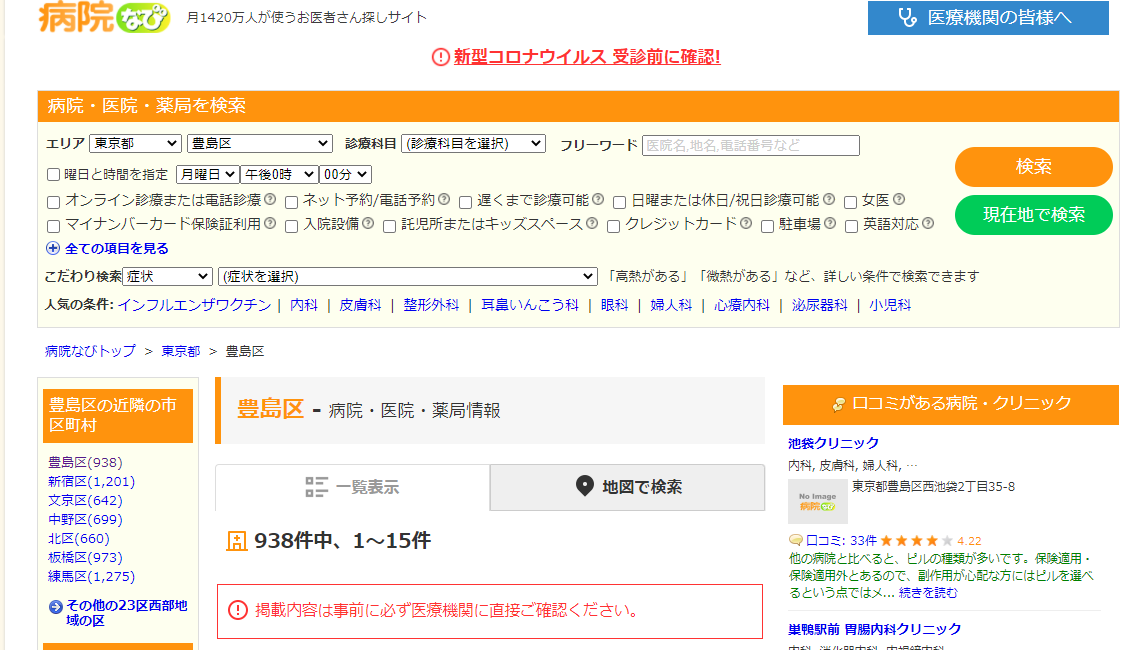
この検索結果から住所や電話番号を抜き出してテキストにしたい
1 医療法人 梅華会東長崎駅前内科クリニック 東京都豊島区長崎4-7-11 マスターズ東長崎1階[地図] 03-5926-9664 休診日:火、日、祝 --- 2 南大塚耳鼻咽喉科クリニック 東京都豊島区南大塚2-42-6 信友大塚ビル5階[地図] 03-6912-0187 休診日:日、祝 ---
PythonのBeautifulSoupを使う
以前appleのサイトをスクレイピングするスクリプトを書いた
mecobalamin.hatenablog.com
やることは
1. 検索結果のソースコードの分析
必要な情報がどのように記述されているか確認する
google Chromeでは
[右クリック]で[ソースを表示]をクリックする
病院なびでは一つの病院の情報は
<div class='corp_header'> ... </div>
のタグの間に書かれている
病院名、住所、電話番号、休診日はそれぞれ次のタグで書かれている
<a class='corp-title__name'>...<a> <div class='corp_address'>...<div> <div class='corp_tel'>...<div> <div class='clinic_hour_holiday'>...<div>
このとき
<div class='corp_header'>
と
<a class='corp-title__name'> <div class='corp_address'> <div class='corp_tel'> <div class='clinic_hour_holiday'>
は入れ子になっていて親と子の関係であり、
子供同士は兄弟である
スクレイピングの手順としては
まずBeautifulSoupのobjectから親のcorp_headerを抜き出す
次に子供のcorp-title__nameを抜き出す
それからcorp-title__nameと兄弟関係にある
corp_address、corp_tel、clinic_hour_holidayを抜き出す
という操作をする
2. 分析を元にPythonのコードを書く
BeautifulSoupのobjectをbsObjとするとき
親である'corp_header'を抜き出す
bsObj.find_all('div', {'class':'corp_header'})
次に子に当たる
'corp-title__name'とその兄弟を抜き出すには
find()とfind_next_sibling()を使う
item_title = i.find('a', {'class':'corp-title__name'}).get_text(strip = True) item_contents = i.find_next_sibling('div', {'class':'corp_contents'}) item_address = item_contents.find('div', {'class':'corp_address'}).get_text(strip = True) item_tel = item_contents.find('div', {'class':'corp_tel'}).get_text(strip = True) item_holiday = item_contents.find('div', {'class':'clinic_hour_holiday'})
3. コードのまとめ
コードをまとめると次のようになる
# -*- coding: utf-8 -*- import urllib from urllib.request import urlopen from bs4 import BeautifulSoup import datetime today = datetime.date.today() todaydetail = datetime.datetime.today() print('----------------------------------') print("Byoinnavi.jp URL") print(todaydetail) print('----------------------------------') urls = ['https://byoinnavi.jp/tokyo/toshimaku', 'https://byoinnavi.jp/tokyo/toshimaku?p=2', 'https://byoinnavi.jp/tokyo/toshimaku?p=3'] n = 1 for url in urls: headers = {"User-Agent": "Mozilla/5.0 (X11; Ubuntu; Linux x86_64; rv:47.0) Gecko/20100101 Firefox/47.0"} request = urllib.request.Request(url, headers = headers) html = urlopen(request).read() bsObj = BeautifulSoup(html, 'html.parser') bsObj_div = bsObj.find_all('div', {'class':'corp_header'}) for i in bsObj_div: print(n) item_title = i.find('a', {'class':'corp-title__name'}).get_text(strip = True) item_contents = i.find_next_sibling('div', {'class':'corp_contents'}) item_address = item_contents.find('div', {'class':'corp_address'}).get_text(strip = True) item_tel = item_contents.find('div', {'class':'corp_tel'}).get_text(strip = True) item_holiday = item_contents.find('div', {'class':'clinic_hour_holiday'}) if item_holiday is None: item_holiday = '' else: item_holiday = item_holiday.get_text(strip = True) print(item_title) print(item_address) print(item_tel) print(item_holiday) print("---") n += 1
以下のサイトを参考にした
403を避けるためにブラウザを偽装している
pythonのurllib.request.Requestで403エラー時の対応方法【ユーザエージェントを偽装する】 | エンジニアステップ
NoneTypeだった場合の処理の仕方
[python]変数がNoneTypeであるかを判定する | akamist blog
Siblingの使い方
BeautifulSoup4で親子、兄弟、前後要素の検索方法 | せなブログ