Atomからvscodeに移行する
Atomの開発が終了した
www.itmedia.co.jp
2022年12月15日を過ぎちゃったけどvscodeに移行するのでその忘備録。
Atomで使っていたのは主にPython, R, LaTeXで、これらをvscodeでも実行できる環境を用意したい
PCにはPython、R、LaTeXをインストール済み
これらの実行ファイルにPATHが通っているのでそのまま利用する
PATHの確認
PATHの確認は、”設定"で”環境変数"を検索して現れる環境変数のウィンドウから行える
ウィンドウの上段はユーザーの環境変数で下段はシステム環境変数である
上段のユーザー環境変数のPATHにPython、R、LaTeXのインストール先が記入されていれば大丈夫
私はそれぞれDドライブにインストールしているので以下のように書かれている
環境によってインストール先が異なるので確認が必要
D:\Python\Python37-32\ D:\R\R-4.2.2\bin D:\texlive\2022\bin\win32
以下のコマンドをPowerShellに入力することでもPATHを確認できる
ヘルプが表示されればPATHが通っている
> python --help > R.exe -h > ptex2pdf -h
やること
- Rのパッケージをインストールする
- vscodeをインストールする
- vscodeに拡張機能をインストールする
- vscodeのsettings.jsonを書き換える
- キーバインドを変更する
- (おまけ)Rの旧バージョンから新バージョンへのRパッケージを移行する
1. Rのパッケージをインストールする
languageserverのインストール
RGuiでインストールする
install.packages("languageserver")
vscDebuggerのインストール
ファイルはCRANのサイトにはないのでvscDebuggerのサポートサイトからダウンロードする
いくつかのファイル形式があるがwindowsの場合はzip形式で良いはず
(tar.gz形式ではインストールできなかった)
manuelhentschel.github.io
RGuiのコマンドラインで
install.packages("/path/to/vscDebugger_0.5.2.zip")
またはPowerShellから
R.exe CMD INSTALL /path/to/vscDebugger_0.5.2.zip
でインストールする
ちなみにRでディレクトリの取得と変更は
getwd() setwd()
を使う
また、サポートサイトにあるように依存関係のある次のパッケージもRGuiからインストールする
install.packages(c('R6', 'jsonlite'))
Rのパッケージ管理についてはこちらのサイトを参考にした
www.task-notes.com
2. vscodeのインストール
ファイルをダウンロードして実行する
code.visualstudio.com
3. vscodeに拡張機能をインストールする
vscode左側のツールバーに拡張機能を使ってインストールする
インストールしたのは
python、R、R Debbuger、LaTeX Workshop、Japanese Language Pack for Visual Studio Code
Marketplaceで拡張機能の名前を検索してインストールした
texファイルをコンパイルできるようにsettings.jsonにコンパイルの設定を記入する
左下の歯車をクリックし、"設定"を開く
"設定”はctrl + ,(コンマ)でも開ける
"設定"タブの右上に"設定(JSON)を開く"ボタンがある
クリックするとsettings.jsonが開き、編集できるようになる
LaTeXのコンパイルにはptex2pdfを、文献リストの作成にはbiberを使う
biberを使ったのはAtomで使っていたから(たぶん)
pbibtexも試してみたが、私の環境ではうまくコンパイルできなかった
biblatex+biberについてはこちらの記事を読ませてもらった
tm23forest.com
settings.jsonの記入方法だが、まずlatex-workshop.latex.toolsにptex2pdfとbiberに必要な引数を定義する
次にtoolsに記入したコマンドをどの様に実行するか、latex-workshop.latex.recipesに記入する
通常のコンパイルならptex2pdfを1回通せばよいが、文献を引用するならptex2pdfのあとにbiberを通し、更にptex2pdfを2回通す
recipesにはその動作を記入する
実際のLaTeX関連の設定は以下の通り
{ "latex-workshop.latex.recipes": [ { "name": "ptex2pdf", "tools": [ "ptex2pdf" ] }, { "name": "ptex2pdf -> biber -> ptex2pdf*2", "tools": [ "ptex2pdf", "biber", "ptex2pdf", "ptex2pdf" ] } ], "latex-workshop.latex.tools": [ { "name": "ptex2pdf", "command": "ptex2pdf", "args": [ "-l", "-ot", "-kanji=utf8 -synctex=1", "%DOCFILE%.tex" ] }, { "name": "biber", "command": "biber", "args": [ "%DOCFILE%" ] } ], "latex-workshop.view.pdf.viewer": "tab", "latex-workshop.latex.autoBuild.cleanAndRetry.enabled": false }
最後の2行は、それぞれ次の設定をする
- pdfファイルをタブで開く
"latex-workshop.view.pdf.viewer": "tab",
- auxファイルを自動で削除しない
"latex-workshop.latex.autoBuild.cleanAndRetry.enabled": false
"自動削除する"にするとコンパイルできなかった
bibtexの記述だけど、エントリーに"_"が入る場合、
バックスラッシュをつけて"\_"とする
5. キーバインドを変更する
AtomのときはCtrl + Shift + Bでスクリプトを実行していた
VS codeではこの組み合わせに割当があるのでCtrl + Shift + Aにスクリプトの実行を割当てた
左下の歯車マークをクリックして
- ”キーボードショートカット"を起動
- "R:Run Souce"をCtrl + Shift + S -> Ctrl + Shift + Aに変更した
- "Python: ターミナルでPythonファイルを実行する"にCtrl + Shift + Aを割当てた
もし他に割当がある場合は警告が出る
6. (おまけ)Rの旧バージョンから新バージョンへのRパッケージを移行する
旧バージョンから新バージョンへRのパッケージの移行
ameblo.jp
CSVファイルから数の集計をする
以前人口ピラミッドのグラフを作成した
mecobalamin.hatenablog.com
同様なグラフを作成するに当たり、以下のようなリストから男女別と年代別に集計をしたい
居住地, 年代, 性別, 死亡確認 死亡例1例目, 非公表, 70代. 非公表, 非公表 死亡例2例目, 非公表, 50代, 男性, 2020年4月19日, 4月7日入院。酸素吸入開始。4月19日死亡確認。死因調査中 死亡例3例目, 那覇市, 80代, 男性, 2020年4月19日, 4月9日入院。4月12日ICUに転院。4月19日死亡確認。死因調査中 死亡例4例目, 中部保健所管内, 70代, 女性, 2020年4月22日, 4月22日死亡確認。死因調査中 死亡例5例目, 中部保健所管内, 70代, 男性, 2020年4月29日, 4月10日発熱。4月12日PCR検査にて陽性を確認、入院。4月29日死亡確認。死因調査中
集計後の出力は以下の通り
| man | worman | undisclosed | |
| 90 + | 71.0 | 143.0 | NaN |
| 80 - 89 | 127.0 | 95.0 | 1.0 |
| 70 - 79 | 90.0 | 37.0 | NaN |
| 60- 69 | 43.0 | 19.0 | NaN |
| 50 - 59 | 15.0 | 6.0 | NaN |
| 40 - 49 | 6.0 | 3.0 | NaN |
| 30 - 39 | 3.0 | 1.0 | NaN |
| 20 - 29 | NaN | NaN | NaN |
| 10 - 19 | NaN | NaN | NaN |
| 0 - 9 | NaN | NaN | NaN |
| undisclosed | 1.0 | NaN | 16.0 |
やることは
- CSVファイルを読み込んでデータフレームに変換
- 文字の変換
- 性別、年齢別に集計
1. CSVファイルを読み込んでデータフレームに変換
CSVを読み込むコードはよく使うので関数にしてある
ファイルのパスとファイル名を引数にした
ファイル名はリストになっている
CSVの読み込みはpandasのread_csvを使用し、1列目をインデックスにした
読み込んだCSVを空のデータフレームに結合して変数を返す
def Read_CSV_Files(Path_CSV, List_CSV): df = DataFrame() for i in List_CSV: try: df_tmp = pd.read_csv(Path_CSV + i, index_col = 0, encoding = 'shift_jis') except Exception as e: print('cannot open file: ', i) print(str(e)) sys.exit(1) else: print('we were able to open the file:', i) df = pd.concat([df, df_tmp]) return df
2. 文字の変換
読み込んだCSVの3列目の型を文字列からpandasのdatetime形式に変換する
日付が"非公表"の場合変換できずにエラーになるため、nanに変換して行ごと削除(dropna())する
df.iloc[:, 3] = df.iloc[:, 3].replace({'非公表': np.nan}).replace({'確認中': np.nan}).dropna() df.iloc[:, 3] = pd.to_datetime(df.iloc[:, 3], format = '%Y年%m月%d日')
3. 性別、年齢別に集計
実行環境ではグラフの出力に2バイト文字を使えないため漢字をアルファベットに変換している
まず性別だけを抜き出し、"Count_age()"で年齢ごとの数をカウントする
df_age = pd.DataFrame()
for i in ['man', 'woman', 'undisclosed']:
df_tmp = df
df_tmp = df_tmp.replace({'男性': 'man', '女性': 'woman', '非公表': 'undisclosed'})
df_tmp = df_tmp[df_tmp['性別'].isin([i])]
df_age = pd.concat([df_age, Count_age(df_tmp.iloc[:, 1])], axis = 1)
df_age.columns = ['man', 'woman', 'undisclosed']
Count_age()はデータフレームを引数にして、インデックスの年代ごとに数をカウントする
def Count_age(df): df_index = {"90歳以上": "90 +", '80代': "80 - 89", '70代': "70 - 79", '60代': "60- 69", '50代': "50 - 59", '40代': "40 - 49", '30代': "30 - 39", '20代': "20 - 29", '10代': "10 - 19", "10歳未満": "0 - 9", "非公表": "undisclosed"} df = df.replace(df_index) df = df.dropna().value_counts() df = df.reindex(index = list(df_index.values())) return df
4. コードのまとめ
コードをまとめると次のようになる
import os, sys, datetime from pandas import Series, DataFrame import pandas as pd import numpy as np def Count_age(df): df_index = {"90歳以上": "90 +", '80代': "80 - 89", '70代': "70 - 79", '60代': "60- 69", '50代': "50 - 59", '40代': "40 - 49", '30代': "30 - 39", '20代': "20 - 29", '10代': "10 - 19", "10歳未満": "0 - 9", "非公表": "undisclosed"} df = df.replace(df_index) df = df.dropna().value_counts() df = df.reindex(index = list(df_index.values())) return df def Read_CSV_Files(Path_CSV, List_CSV): df = DataFrame() for i in List_CSV: try: df_tmp = pd.read_csv(Path_CSV + i, index_col = 0, encoding = 'shift_jis') except Exception as e: print('cannot open file: ', i) print(str(e)) sys.exit(1) else: print('we were able to open the file:', i) df = pd.concat([df, df_tmp]) return df if __name__ == '__main__': path = os.getcwd() path = os.chdir(os.path.dirname(os.path.abspath(__file__))) path = os.getcwd() List_DeathList = ['hogehoge.csv'] Path_CSV = path + '\\' + 'csv\\' df = Read_CSV_Files(Path_CSV, List_DeathList) df.iloc[:, 3] = df.iloc[:, 3].replace({'非公表': np.nan}).replace({'確認中': np.nan}).dropna() df.iloc[:, 3] = pd.to_datetime(df.iloc[:, 3], format = '%Y年%m月%d日') df_age = pd.DataFrame() for i in ['man', 'woman', 'undisclosed']: df_tmp = df df_tmp = df_tmp.replace({'男性': 'man', '女性': 'woman', '非公表': 'undisclosed'}) df_tmp = df_tmp[df_tmp['性別'].isin([i])] df_age = pd.concat([df_age, Count_age(df_tmp.iloc[:, 1])], axis = 1) df_age.columns = ['man', 'woman', 'undisclosed'] print(df_age)
いちいちコードを書いたけど何かしらもっと便利な方法が他にあるとは思う
サイトの検索結果をスクレイピングする
まとめサイトの検索結果がある
例えば病院を探すサイト、病院なびを使う
東京都豊島区で探すと938件表示される
https://byoinnavi.jp/tokyo/toshimaku
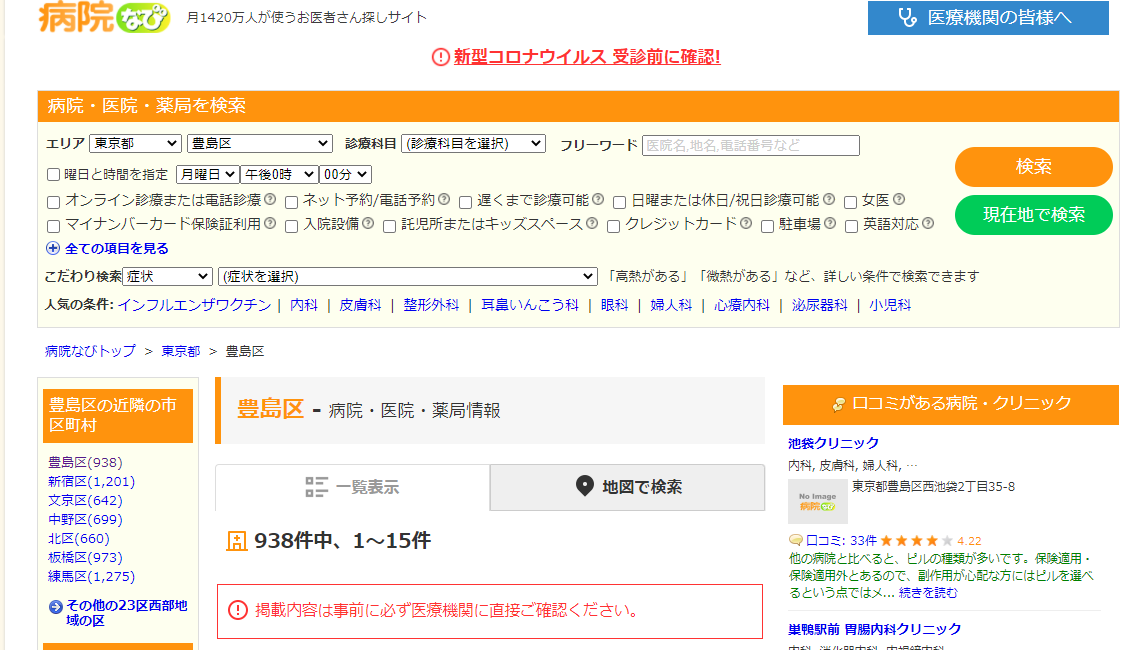
この検索結果から住所や電話番号を抜き出してテキストにしたい
1 医療法人 梅華会東長崎駅前内科クリニック 東京都豊島区長崎4-7-11 マスターズ東長崎1階[地図] 03-5926-9664 休診日:火、日、祝 --- 2 南大塚耳鼻咽喉科クリニック 東京都豊島区南大塚2-42-6 信友大塚ビル5階[地図] 03-6912-0187 休診日:日、祝 ---
PythonのBeautifulSoupを使う
以前appleのサイトをスクレイピングするスクリプトを書いた
mecobalamin.hatenablog.com
やることは
1. 検索結果のソースコードの分析
必要な情報がどのように記述されているか確認する
google Chromeでは
[右クリック]で[ソースを表示]をクリックする
病院なびでは一つの病院の情報は
<div class='corp_header'> ... </div>
のタグの間に書かれている
病院名、住所、電話番号、休診日はそれぞれ次のタグで書かれている
<a class='corp-title__name'>...<a> <div class='corp_address'>...<div> <div class='corp_tel'>...<div> <div class='clinic_hour_holiday'>...<div>
このとき
<div class='corp_header'>
と
<a class='corp-title__name'> <div class='corp_address'> <div class='corp_tel'> <div class='clinic_hour_holiday'>
は入れ子になっていて親と子の関係であり、
子供同士は兄弟である
スクレイピングの手順としては
まずBeautifulSoupのobjectから親のcorp_headerを抜き出す
次に子供のcorp-title__nameを抜き出す
それからcorp-title__nameと兄弟関係にある
corp_address、corp_tel、clinic_hour_holidayを抜き出す
という操作をする
2. 分析を元にPythonのコードを書く
BeautifulSoupのobjectをbsObjとするとき
親である'corp_header'を抜き出す
bsObj.find_all('div', {'class':'corp_header'})
次に子に当たる
'corp-title__name'とその兄弟を抜き出すには
find()とfind_next_sibling()を使う
item_title = i.find('a', {'class':'corp-title__name'}).get_text(strip = True) item_contents = i.find_next_sibling('div', {'class':'corp_contents'}) item_address = item_contents.find('div', {'class':'corp_address'}).get_text(strip = True) item_tel = item_contents.find('div', {'class':'corp_tel'}).get_text(strip = True) item_holiday = item_contents.find('div', {'class':'clinic_hour_holiday'})
3. コードのまとめ
コードをまとめると次のようになる
# -*- coding: utf-8 -*- import urllib from urllib.request import urlopen from bs4 import BeautifulSoup import datetime today = datetime.date.today() todaydetail = datetime.datetime.today() print('----------------------------------') print("Byoinnavi.jp URL") print(todaydetail) print('----------------------------------') urls = ['https://byoinnavi.jp/tokyo/toshimaku', 'https://byoinnavi.jp/tokyo/toshimaku?p=2', 'https://byoinnavi.jp/tokyo/toshimaku?p=3'] n = 1 for url in urls: headers = {"User-Agent": "Mozilla/5.0 (X11; Ubuntu; Linux x86_64; rv:47.0) Gecko/20100101 Firefox/47.0"} request = urllib.request.Request(url, headers = headers) html = urlopen(request).read() bsObj = BeautifulSoup(html, 'html.parser') bsObj_div = bsObj.find_all('div', {'class':'corp_header'}) for i in bsObj_div: print(n) item_title = i.find('a', {'class':'corp-title__name'}).get_text(strip = True) item_contents = i.find_next_sibling('div', {'class':'corp_contents'}) item_address = item_contents.find('div', {'class':'corp_address'}).get_text(strip = True) item_tel = item_contents.find('div', {'class':'corp_tel'}).get_text(strip = True) item_holiday = item_contents.find('div', {'class':'clinic_hour_holiday'}) if item_holiday is None: item_holiday = '' else: item_holiday = item_holiday.get_text(strip = True) print(item_title) print(item_address) print(item_tel) print(item_holiday) print("---") n += 1
以下のサイトを参考にした
403を避けるためにブラウザを偽装している
pythonのurllib.request.Requestで403エラー時の対応方法【ユーザエージェントを偽装する】 | エンジニアステップ
NoneTypeだった場合の処理の仕方
[python]変数がNoneTypeであるかを判定する | akamist blog
Siblingの使い方
BeautifulSoup4で親子、兄弟、前後要素の検索方法 | せなブログ
iOSのショートカットでJSONファイルを使う
iOSのショートカットアプリでJSONファイルを使えたのでメモ
目的はショートカットアプリで
ポケモンの攻撃と防御の相性を表示すること
相性の組み合わせをJSONファイルに記録した
どっかのサイトを見ながら入力したので
間違っているところもあるかも
ちなみに公式のポケモンオンラインストアで定価は6,578円 (税込)
ここから本題
jsonとは
JavaScript Object Notation - Wikipedia
JSONとは | オラクル | Oracle 日本
大きくやることは2つ
- JSONファイルの作成
- ショートカットアプリの編集
作成したJSONファイルはpokemon.jsonとして
iCloud以下の/Shortcuts/pokemon/に保存した
ファイルの内容はこの記事の最後に掲載した
ショートカットアプリでやることは
- JSONファイルの読み込み
- ファイルから辞書を読み込み
- 辞書から選択肢を作成
- 選択した項目の値を取得
- 値からテキストを作成して表示する
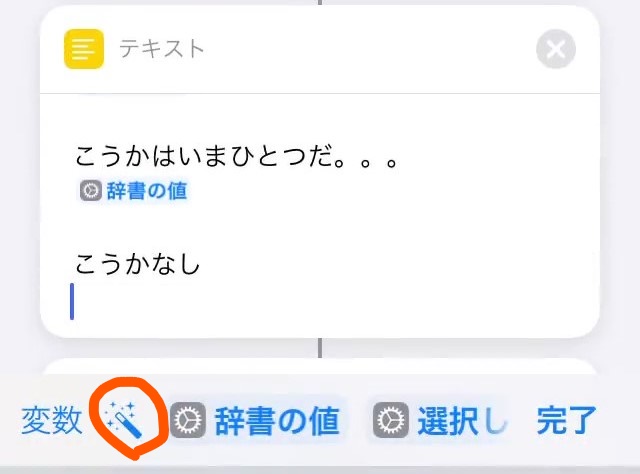
ポイントは変数をマジック変数で取得すること
他の言語の感覚だと変数を用意して
代入して使用するが
マジック変数を使うと変数を定義しなくても
任意の場所に任意の変数を読み込める
これは視覚的にプログラミングできて便利
マジック変数は赤丸で
囲んだボタンを使って取得する
実際の作業はここから
ショートカットアプリの編集
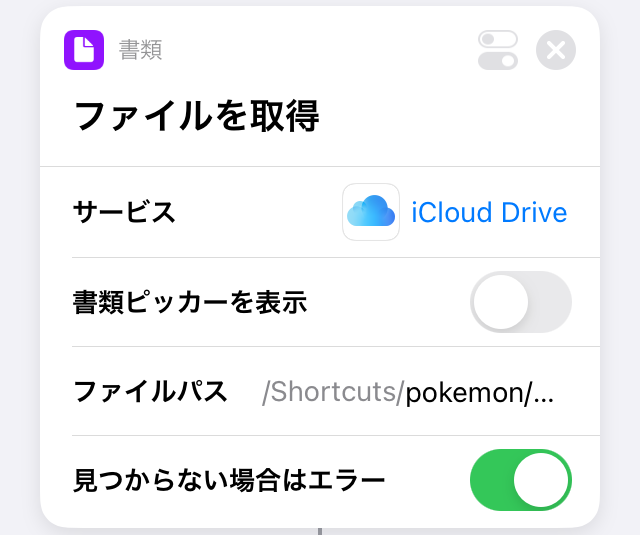
1. JSONファイルの読み込み
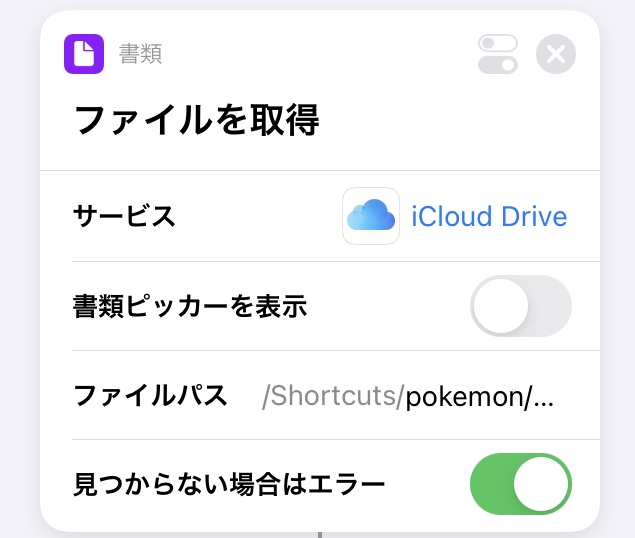
JSONファイルのパスを設定する
サービスをiCloud
ファイルパスを/Shortcuts/pokemon/
ファイル名をpokemon.json
とした
2. ファイルから辞書を読み込み
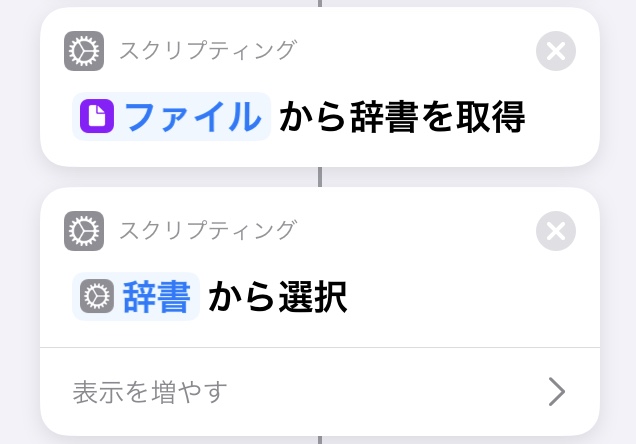
アクションの検索から
"入力から辞書を取得"を選択
入力が"辞書"以外なら消去して
マジック変数を選択、
1.で読み込んだファイルを指定する
3. 辞書から選択肢を作成
アクションの検索から
"リストから選択"を選ぶ
入力が"辞書"以外なら消去して
マジック変数を使って
2.で取得した辞書を指定する
4. 選択した項目の値を取得
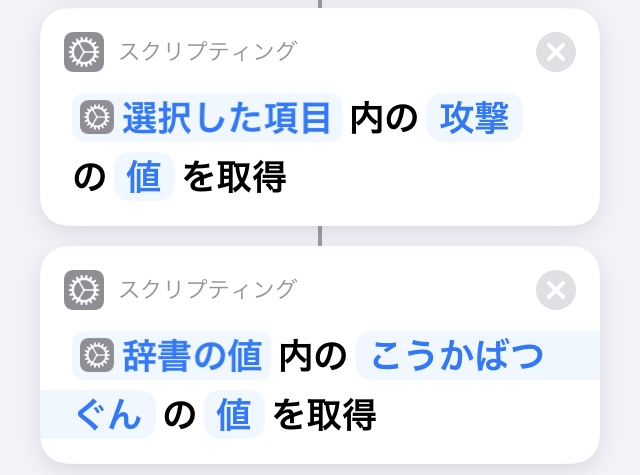
アクションの検索から
"辞書の値を取得"を選ぶ
入力はマジック変数を使って
3.で"辞書の値"を選び
キーに"こうかばつぐん"を入力する
同様に"こうかいまひとつ"、
"こうかなし"を入力したアクションも作成する
5. 値からテキストを作成して表示する
出力するテキストも
マジック変数を使って
4.で取得した辞書の値を選択する
実行するとJSONをもとに作られた
選択が表示される

技のタイプを選ぶと
技の相性のリストが表示される

アクションは以下のように使った
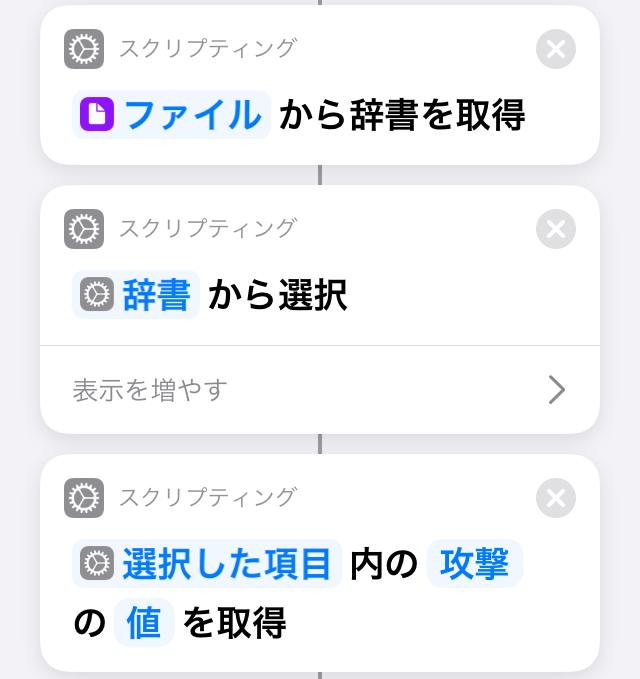




使用したjsonファイルは以下の通り
pokemon.json
{ "ノーマル": { "攻撃": { "こうかばつぐん":["なし"], "こうかいまひとつ":["いわ", "はがね"], "こうかなし":["ゴースト"] }, "防御": { "こうかばつぐん":["かくとう"], "こうかいまひとつ":["なし"], "こうかなし":["ゴースト"] } }, "ほのお": { "攻撃": { "こうかばつぐん":["くさ", "こおり", "むし", "はがね"], "こうかいまひとつ":["ほのお", "みず", "いわ", "ドラゴン"], "こうかなし":["なし"] }, "防御": { "こうかばつぐん":["みず", "じめん", "いわ"], "こうかいまひとつ":["ほのお", "くさ", "こおり", "むし", "はがね", "フェアリー"], "こうかなし":["なし"] } }, "みず": { "攻撃": { "こうかばつぐん":["ほのお", "じめん", "いわ"], "こうかいまひとつ":["みず", "くさ", "ドラゴン"], "こうかなし":["なし"] }, "防御": { "こうかばつぐん":["でんき", "くさ"], "こうかいまひとつ":["ほのお", "みず", "こおり", "はがね"], "こうかなし":["なし"] } }, "くさ": { "攻撃": { "こうかばつぐん":["みず", "じめん", "いわ"], "こうかいまひとつ":["ほのお", "くさ", "どく", "ひこう", "むし", "ドラゴン", "はがね"], "こうかなし":["なし"] }, "防御": { "こうかばつぐん":["ほのお", "こおり", "どく", "ひこう", "むし"], "こうかいまひとつ":["みず", "でんき", "くさ", "じめん"], "こうかなし":["なし"] } }, "でんき": { "攻撃": { "こうかばつぐん":["みず", "ひこう"], "こうかいまひとつ":["でんき", "くさ", "ドラゴン"], "こうかなし":["じめん"] }, "防御": { "こうかばつぐん":["じめん"], "こうかいまひとつ":["でんき", "ひこう", "はがね"], "こうかなし":["なし"] } }, "こおり": { "攻撃": { "こうかばつぐん":["くさ", "じめん", "ひこう", "ドラゴン"], "こうかいまひとつ":["ほのお", "みず", "こおり", "はがね"], "こうかなし":["なし"] }, "防御": { "こうかばつぐん":["ほのお", "かくとう", "いわ", "はがね"], "こうかいまひとつ":["こおり"], "こうかなし":["なし"] } }, "かくとう": { "攻撃": { "こうかばつぐん":["ノーマル", "こおり", "いわ", "あく", "はがね"], "こうかいまひとつ":["どく", "ひこう", "エスパー", "むし", "フェアリー"], "こうかなし":["ゴースト"] }, "防御": { "こうかばつぐん":["ひこう", "エスパー", "フェアリー"], "こうかいまひとつ":["むし", "いわ", "あく"], "こうかなし":["ゴースト"] } }, "どく": { "攻撃": { "こうかばつぐん":["くさ", "フェアリー"], "こうかいまひとつ":["どく", "じめん", "いわ", "ゴースト"], "こうかなし":["はがね"] }, "防御": { "こうかばつぐん":["じめん", "エスパー"], "こうかいまひとつ":["くさ", "かくとう", "どく", "むし", "フェアリー"], "こうかなし":["なし"] } }, "じめん": { "攻撃": { "こうかばつぐん":["ほのお", "でんき", "どく", "いわ", "はがね"], "こうかいまひとつ":["くさ", "むし"], "こうかなし":["ひこう"] }, "防御": { "こうかばつぐん":["みず", "じめん", "こおり"], "こうかいまひとつ":["どく", "いわ"], "こうかなし":["でんき"] } }, "ひこう": { "攻撃": { "こうかばつぐん":["Glound", "かくとう", "むし"], "こうかいまひとつ":["でんき", "いわ", "はがね"], "こうかなし":["なし"] }, "防御": { "こうかばつぐん":["でんき", "こおり", "いわ"], "こうかいまひとつ":["くさ", "かくとう", "むし"], "こうかなし":["じめん"] } }, "エスパー": { "攻撃": { "こうかばつぐん":["かくとう", "どく"], "こうかいまひとつ":["エスパー", "はがね"], "こうかなし":["ゴースト"] }, "防御": { "こうかばつぐん":["むし", "ゴースト", "あく"], "こうかいまひとつ":["かくとう", "エスパー"], "こうかなし":["なし"] } }, "むし": { "攻撃": { "こうかばつぐん":["くさ", "エスパー", "ゴースト"], "こうかいまひとつ":["ほのお", "かくとう", "どく", "ひこう", "ゴースト", "はがね", "フェアリー"], "こうかなし":["なし"] }, "防御": { "こうかばつぐん":["ほのお", "ひこう", "いわ"], "こうかいまひとつ":["くさ", "かくとう", "じめん"], "こうかなし":["なし"] } }, "いわ": { "攻撃": { "こうかばつぐん":["ほのお", "こおり", "ひこう", "むし"], "こうかいまひとつ":["かくとう", "じめん", "はがね"], "こうかなし":["なし"] }, "防御": { "こうかばつぐん":["みず", "くさ", "かくとう", "じめん", "はがね"], "こうかいまひとつ":["ノーマル", "ほのお", "どく", "ひこう"], "こうかなし":["なし"] } }, "ゴースト": { "攻撃": { "こうかばつぐん":["エスパー", "ゴースト"], "こうかいまひとつ":["あく"], "こうかなし":["ノーマル"] }, "防御": { "こうかばつぐん":["ゴースト", "あく"], "こうかいまひとつ":["どく", "むし"], "こうかなし":["ノーマル", "かくとう"] } }, "ドラゴン": { "攻撃": { "こうかばつぐん":["ドラゴン"], "こうかいまひとつ":["はがね"], "こうかなし":["フェアリー"] }, "防御": { "こうかばつぐん":["こおり", "ドラゴン", "フェアリー"], "こうかいまひとつ":["ほのお", "みず", "でんき", "くさ"], "こうかなし":["なし"] } }, "あく": { "攻撃": { "こうかばつぐん":["エスパー", "ゴースト"], "こうかいまひとつ":["かくとう", "あく", "フェアリー"], "こうかなし":["なし"] }, "防御": { "こうかばつぐん":["かくとう", "むし", "フェアリー"], "こうかいまひとつ":["ゴースト", "あく"], "こうかなし":["エスパー"] } }, "はがね": { "攻撃": { "こうかばつぐん":["こおり", "いわ", "フェアリー"], "こうかいまひとつ":["ほのお", "みず", "でんき", "はがね"], "こうかなし":["なし"] }, "防御": { "こうかばつぐん":["ほのお", "かくとう", "じめん"], "こうかいまひとつ":["ノーマル", "くさ", "こおり", "ひこう", "エスパー", "むし", "いわ", "ドラゴン", "はがね", "フェアリー"], "こうかなし":["どく"] } }, "フェアリー": { "攻撃": { "こうかばつぐん":["かくとう", "ドラゴン", "あく"], "こうかいまひとつ":["ほのお", "どく", "はがね"], "こうかなし":["なし"] }, "防御": { "こうかばつぐん":["どく", "はがね"], "こうかいまひとつ":["かくとう", "むし", "あく"], "こうかなし":["ドラゴン"] } } }
Pythonで時系列グラフに水平線と矢印を入れる
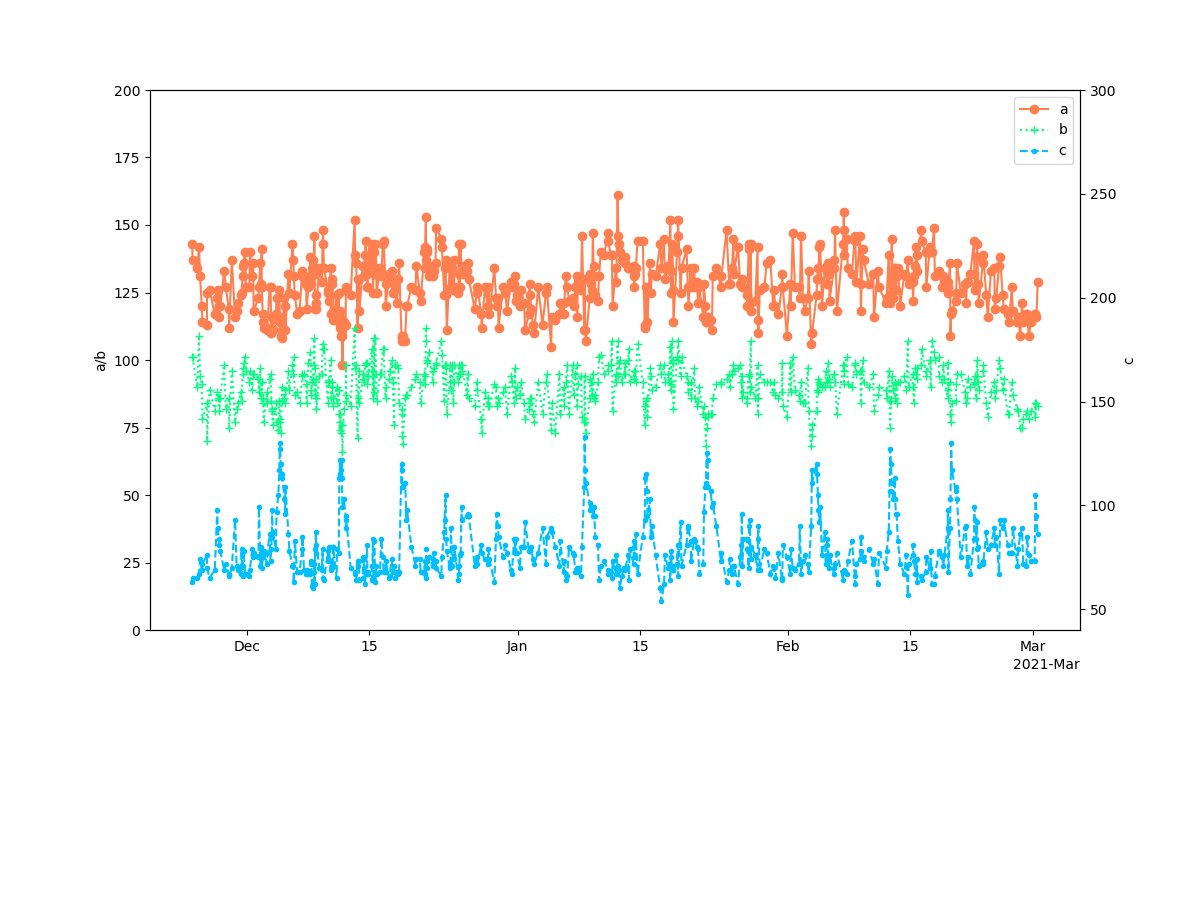
以前Pythonで時系列グラフを作成した
mecobalamin.hatenablog.com
このグラフに矢印と水平線を加える
つまりこのグラフの任意の場所に矢印と水平線を加えて
このようにする
元のデータはCSVで500行ぐらいある
その一部を抜粋
Date, a, b, c, d 2020/11/24 16:42:20, 143, 101, 63, 2020/11/24 17:27:19, 137, 101, 65, 2020/11/25 06:31:48, 134, 90, 65, 2020/11/25 11:21:57, 142, 109, 67, 2020/11/25 14:06:42, 131, 94, 74, 2020/11/25 18:54:18, 120, 91, 69, 2020/11/25 20:42:53, 114, 78, 72, 2020/11/26 09:09:53, 113, 84, 76, 2020/11/26 09:17:28, 125, 70, 70, 1021.67 2020/11/26 16:12:06, 126, 89, 65, 1019.64 2020/11/27 06:37:47, 117, 81, 69, 1020.66 2020/11/27 13:31:37, 123, 88, 98, 1019.98 2020/11/27 14:22:03, 126, 86, 89, 1019.64 2020/11/27 17:58:24, 120, 86, 84, 1020.32 2020/11/27 19:35:42, 116, 81, 81, 1021 2020/11/27 21:35:24, 120, 86, 78, 1021.33 2020/11/28 08:30:20, 133, 98, 69, 1022.69 2020/11/28 12:59:11, 127, 82, 72, 1022.01 2020/11/28 20:59:20, 119, 86, 67, 1022.69 2020/11/28 22:06:02, 112, 75, 66, 1023.03
dfという変数に格納されている
今回のポイントは
- axesオブジェクトを返す
- 矢印をいれる関数を作成する
- 水平線はplot関数を使う
1. axesオブジェクトを返す
グラフを作成する関数を書いてある
関数の内部に矢印を入れる命令を書いてもいいのだが
汎用性をもたせたいのでグラフと矢印の描画を分けたい
グラフを以下のようにして描く
fig = plt.figure(figsize = (12.0, 9.0)) ax1 = fig.subplots()
グラフを書いたaxesオブジェクトをretrunで戻す
return ax1
matplotlibについてはこちらを参考にした
matplotlibの描画の基本 - figやらaxesやらがよくわからなくなった人向け - Qiita
2. 矢印をいれる関数を作成する
グラフのデータdfはgraph_dataに入っている
関数の引数として
矢印を書き込むaxesオブジェクト、
矢印の色、矢印の長さ
を渡す
矢印は上下方向にしか引かないので
矢印の長さで向きを示す
正の値が下向き、負の値が上向きになる
日付と矢印を入れるy軸の値で
インスタンスを生成し、
矢印を書き込む関数(メソッド)を呼び出す
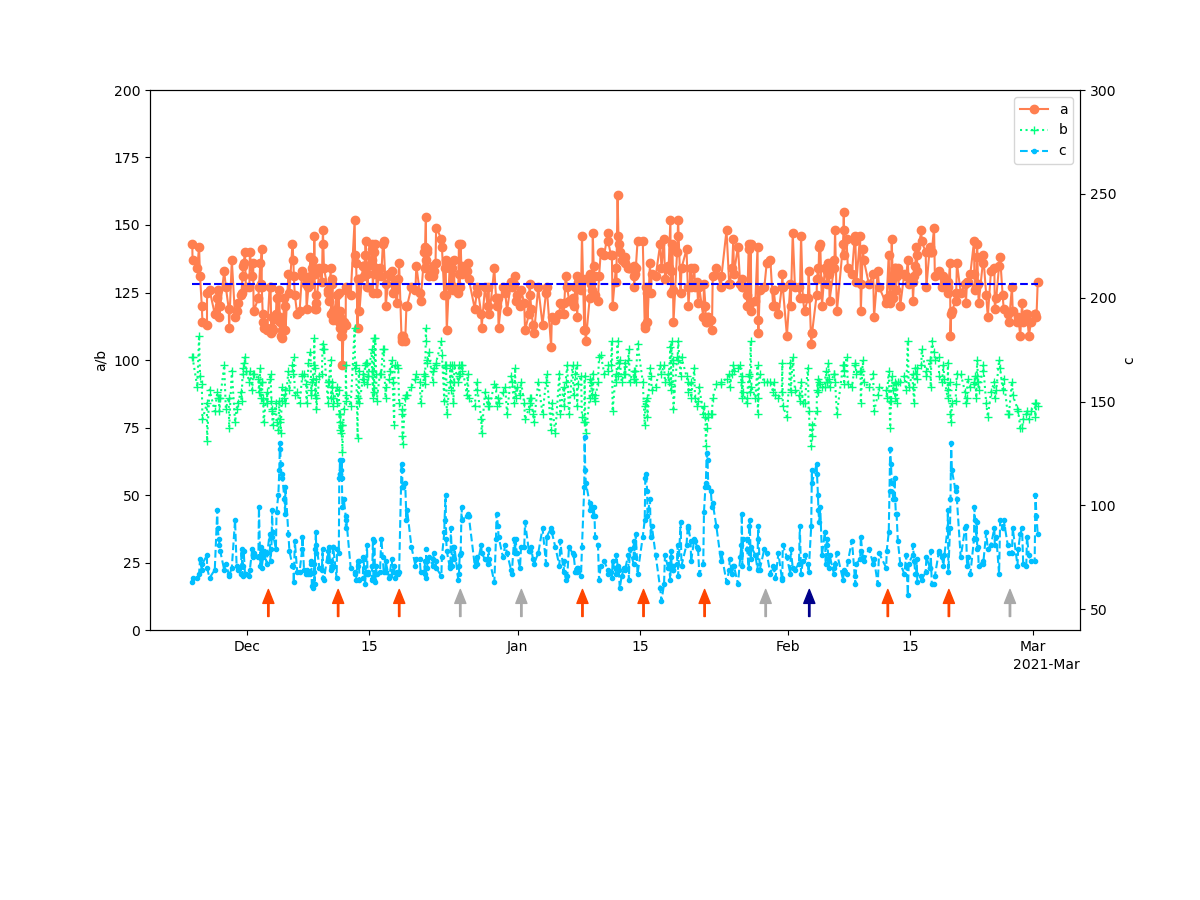
CreateGraphs({'2020-12-03 10:00:00':'15', '2020-12-11 10:00:00':'15', '2020-12-18 10:00:00':'15', '2021-01-08 10:00:00':'15', '2021-01-15 10:00:00':'15', '2021-01-22 10:00:00':'15', '2021-02-12 10:00:00':'15', '2021-02-19 10:00:00':'15'}).add_arrows(ax, '#ff4500', -10)
この場合は8個の矢印を描く
矢印を書き込む関数は以下の通り
def add_arrows(self, ax, arrow_color, arrow_direction): values_infection = self.graph_data date_infection = values_infection.keys() for key in date_infection: ax.annotate("", xy = (pd.to_datetime(key), int(values_infection[key])), xytext = (pd.to_datetime(key), int(values_infection[key]) + arrow_direction), arrowprops = dict(shrink = 0, width = 1, headwidth = 8, headlength = 10, connectionstyle = 'arc3', facecolor = arrow_color, edgecolor = arrow_color))
iOSのPythonista3ではheadlengthに関してエラーが出る
環境によってはarrowpropsを以下のように書き換える必要があるかも
arrowprops = dict(arrowstyle = '->, head_width = 0.2, head_length = 0.5', connectionstyle = 'arc3', facecolor = arrow_color, edgecolor = arrow_color)
3. 水平線はplot関数を使う
水平線を入れるメソッドhlinesもあるが
グラフの値を重ねられてしまう
ax.hlines([128], min(df.index), max(df.index), "blue", linestyles = 'dashed')
コードの最後に書いてもグラフに隠れる
そこでplot()を使って水平線を描く
ax.plot([min(df.index), max(df.index)],[128, 128], "blue", linestyle='dashed')
コードをまとめるとこの様になる
# -*- coding: utf-8 -*- import os, sys, datetime from pandas import Series, DataFrame import pandas as pd import numpy as np import matplotlib.pyplot as plt import matplotlib.dates as mdates import seaborn as sns class ReadFiles: def __init__(self): pass def get_current_path(self): current_path = os.getcwd() current_path = os.chdir(os.path.dirname(os.path.abspath(__file__))) current_path = os.getcwd() return(current_path) def create_directories(self, path_to_dir): try: os.makedirs(path_to_dir) except FileExistsError: pass def read_files(self, path_to_file): print('open a csv file.') try: df = pd.read_csv(path_to_file) except Exception as e: print('cannot open file: ', path_to_file) print(str(e)) sys.exit(1) else: print('Success!') return(df) class CreateGraphs: def __init__(self, graph_data): self.graph_data = graph_data def create_line_graph(self): print('Create line plot') df = self.graph_data fig = plt.figure(figsize = (12.0, 9.0)) ax1 = fig.subplots() plt.subplots_adjust(left=0.125, right=0.9, bottom=0.3, top=0.9) plt.ylim(0, 200) plt.ylabel('a/b') ax1.plot(df.index, df.iloc[:, 0], linestyle = '-', marker = 'o', color = '#ff7f50', label = df.columns[0]) ax1.plot(df.index, df.iloc[:, 1], linestyle = ':', marker = '+', color = '#00ff7f', label = df.columns[1]) ax2 = ax1.twinx() plt.ylim(40, 300) plt.ylabel('c') ax2.plot(df.index, df.iloc[:, 2], linestyle = '--', marker = '.', color = '#00bfff', label = df.columns[2]) locator = mdates.AutoDateLocator() formatter = mdates.ConciseDateFormatter(locator) ax1.xaxis.set_major_locator(locator) ax1.xaxis.set_major_formatter(formatter) handles1, labels1 = ax1.get_legend_handles_labels() handles2, labels2 = ax2.get_legend_handles_labels() ax1.legend(handles1 + handles2, labels1 + labels2, loc = 'upper right') return ax1 def add_arrows(self, ax, arrow_color, arrow_direction): values_infection = self.graph_data date_infection = values_infection.keys() for key in date_infection: ax.annotate("", xy = (pd.to_datetime(key), int(values_infection[key])), xytext = (pd.to_datetime(key), int(values_infection[key]) + arrow_direction), arrowprops = dict(shrink = 0, width = 1, headwidth = 8, headlength = 10, connectionstyle = 'arc3', facecolor = arrow_color, edgecolor = arrow_color)) if __name__ == '__main__': date_today = datetime.date.today() day_save_file = str(date_today.year) + str(date_today.month).zfill(2) + str(date_today.day).zfill(2) input_file_name = 'Python_Sample.csv' output_dir_name = 'graph' output_graph_name = day_save_file + '_graph_sample.png' path_input_file = ReadFiles().get_current_path() + '\\' + input_file_name path_output_dir = ReadFiles().get_current_path() + '\\' + output_dir_name + '\\' print(path_input_file) ReadFiles().create_directories(path_output_dir) df = ReadFiles().read_files(path_input_file) print(df.iloc[-1]) print(df.mean()) df['Date'] = pd.to_datetime(df['Date']) df = df.set_index('Date') ax = CreateGraphs(df).create_line_graph() CreateGraphs({'2020-12-03 10:00:00':'15', '2020-12-11 10:00:00':'15', '2020-12-18 10:00:00':'15', '2021-01-08 10:00:00':'15', '2021-01-15 10:00:00':'15', '2021-01-22 10:00:00':'15', '2021-02-12 10:00:00':'15', '2021-02-19 10:00:00':'15'}).add_arrows(ax, '#ff4500', -10) CreateGraphs({'2020-12-25 10:00:00':'15', '2021-01-01 10:00:00':'15', '2021-01-29 10:00:00':'15', '2021-02-26 10:00:00':'15'}).add_arrows(ax, '#a9a9a9', -10) CreateGraphs({'2021-02-03 10:00:00':'15'}).add_arrows(ax, '#00008b', -10) ax.plot([min(df.index), max(df.index)],[128, 128], "blue", linestyle='dashed') plt.savefig(path_output_dir + '\\' + output_graph_name) plt.close() print('Operation completed')
メモ: DockerでNginxを使う
使い方を忘れていたのでメモ
まずDocker machineの起動と終了
$ docker-machine.exe start $ docker-machine.exe stop
Nginxの起動
$ docker run --rm -v /e/www:/usr/share/nginx/html -d -p 8080:80 --name nginx nginx
起動中のコンテナの確認
$ docker ps CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES ea3663501739 nginx "/docker-entrypoint.…" 27 seconds ago Up 27 seconds 0.0.0.0:8080->80/tcp nginx
コンテナの終了
$ docker stop nginx
コンテナイメージのリスト
$ docker images REPOSITORY TAG IMAGE ID CREATED SIZE nginx latest 992e3b7be046 4 months ago 133MB ubuntu latest 9140108b62dc 4 months ago 72.9MB
Windowsのブラウザからアクセスするには
http://192.168.3.4:8000/
wslのifconfigでwifi0のIPアドレスを確認する
ポートの設定は過去記事を参照する
mecobalamin.hatenablog.com
Pythonを使って人口ピラミッドのグラフを作る
Pythonのseabornを使って以下のような人口ピラミッドのグラフを作りたい

元のデータ
| man | woman | |
|---|---|---|
| 90+ | 47.0 | 128.0 |
| 80 - 89 | 174.0 | 205.0 |
| 70 - 79 | 321.0 | 257.0 |
| 60- 69 | 562.0 | 393.0 |
| 50 - 59 | 604.0 | 442.0 |
| 40 - 49 | 730.0 | 501.0 |
| 30 - 39 | 670.0 | 478.0 |
| 20 - 29 | 895.0 | 717.0 |
| 10 - 19 | 309.0 | 258.0 |
| 0 - 9 | 123.0 | 132.0 |
| Undisclosed | 2.0 | 8.0 |
| Missing number | NaN | NaN |
ここのやり方を参考にさせてもらった
Python3のmatplotlibを使ったヒストグラムの作図
上記の表はdf_ageという変数に入っているとする
型はpandasのDataFrame
print(df_age) man woman 90+ 47.0 128.0 80 - 89 174.0 205.0 70 - 79 321.0 257.0 60- 69 562.0 393.0 50 - 59 604.0 442.0 40 - 49 730.0 501.0 30 - 39 670.0 478.0 20 - 29 895.0 717.0 10 - 19 309.0 258.0 0 - 9 123.0 132.0 Undisclosed 2.0 8.0 Missing number NaN NaN print(type(df_age)) <class 'pandas.core.frame.DataFrame'>
男女のデータを一つのヒストグラムに描画する
今回キモになっているのは以下の3つ
- データの反転
- 一つの図に2つのグラフを書き込む
- 軸の書き換え
データの反転
参考にしたサイトにも説明されているが
片方のデータを負の値に反転させている
df_age["man"] *= -1
一つの図に2つのグラフを書き込む
seabornのbarplotを使っている
zip関数を使ってman/womanのデータを
うまく選択している
for name, color in zip(age_names, age_colors): sns.barplot(x = name, y = df_age.index, data = df_age, color = color, label = name, orient = 'h', order = df_age.index, ax = ax)
zip関数
Python, zip関数の使い方: 複数のリストの要素をまとめて取得 | note.nkmk.me
軸の書き換え
横軸が負->正となるので
グラフの中心を0として
両側に正の値になるように
ラベルを書き換える
ax.set_xticklabels(['1000', '750', '500', '250', '0', '250', '500', '750', '1000'])
コードを以下にまとめる
import pandas as pd import seaborn as sns import matplotlib.pyplot as plt sns.set(style = 'whitegrid') fig, ax = plt.subplots(figsize = (7, 5)) plt.subplots_adjust(left = 0.2, right = 0.85, bottom = 0.05, top = 1.0) df_age["man"] *= -1 age_colors = ["#4169e1", "#ff1493"] age_names = df_age.columns for name, color in zip(age_names, age_colors): sns.barplot(x = name, y = df_age.index, data = df_age, color = color, label = name, orient = 'h', order = df_age.index, ax = ax) ax.set_xlabel("") ax.set_ylabel("age", fontsize = 12) ax.set_xlim(-1000, 1000) ax.set_xticklabels(['1000', '750', '500', '250', '0', '250', '500', '750', '1000']) ax.legend(loc = 'lower left') plt.savefig('graph.png') plt.close()
16 September 2022 追記
データを集計するスクリプトを書いた
mecobalamin.hatenablog.com