WSLで動くDockerのストレージサイズを変える
WSLで動くDockerでTrinityを動かしたい
Trinityについては過去記事を参照
mecobalamin.hatenablog.com
Ubuntuのイメージを実行して
足りないコマンドをインストールして
Trinityを動かせたがストレージサイズが足りなくて途中で止まった
そこでWSLで動くDockerのストレージサイズを変更する
実際にはストレージサイズの大きなVirtual Machineを新しく作った
Docker tool boxを利用してWSLでDockerを使えるようにした
mecobalamin.hatenablog.com]
Docker tool boxをインストールすると
ストレージサイズが20GBのVirtual Machineが作られる
このストレージのサイズを変更できないか調べてみたが
どうもできないらしい
自動で作られるストレージの実体は
VMDKという拡張子のつくファイルで
この種類の仮想ハードディスクはサイズの変更ができない
そこでWSLからDocker-machine.exeを使って
ストレージサイズの大きなVirtual Machineを作成する
virtual machineを停止した状態で
以下のコマンドをWSLで実行する
docker-machine.exe create --driver virtualbox --virtualbox-disk-size "120000" --virtualbox-memory "16384" ubuntu
virtualbox-disk-sizeで仮想ハードディスクのサイズ
virtualbox-memoryでVirtual Machineのメモリのサイズを指定する
最後のubuntuは新しいvirtual machineの名前になる
ちなみにvirtual machineの停止は
docker-machine.exe stop
virtual machineが作成されたら
docker-machine.exe configを使って
ホストのアドレスと
ファイルのあるディレクトリを
$HOME/.profileに記入する
作成したvirtual machineのubuntuが動いているときに
docker-machine.exe configを実行すると
以下のパラメータが表示される
$ docker-machine.exe config ubuntu --tlsverify --tlscacert="C:\\Users\\hogehoge\\.docker\\machine\\machines\\ubuntu\\ca.pem" --tlscert="C:\\Users\\hogehoge\\.docker\\machine\\machines\\ubuntu\\cert.pem" --tlskey="C:\\Users\\hogehoge\\.docker\\machine\\machines\\ubuntu\\key.pem" -H=tcp://192.168.99.104:2376
hogehogeはwindowsにログインしているユーザー名
このうち
C:\\Users~\\ubuntu
と
tcp://192.168.99.104:2376
を$HOME/.profileに記入する
export DOCKER_HOST="tcp://192.168.99.104:2376" export DOCKER_CERT_PATH=/c/Users/hogehoge/.docker/machine/machines/ubuntu/ export DOCKER_TLS_VERIFY=1
記入が終わったら
$ source ~/.profile
を実行して読み直す
これでvirtual machineを実行できる
$ docker-machine.exe start ubuntu
virtual machineの名前は必要
つけないとdefaultのvirtual machineが実行される
いまのところ新しく作ったviertual machineは
docker-machine.exe envとdocker-machine.exe activeでは
確認できていない
このvirtual machineに
ubuntuのimageをダウンロードするなり
これまで作ったimageをloadするなりして
環境をつくれる
pythonで計算問題をつくる
小学校が休校になって一ヶ月以上になる
自宅学習をさせているけど
計算問題をこなす数が足りない気がしたので
pythonの勉強も兼ねてiPadのpythonisata3を使って
ランダムに計算問題を作るスクリプトを書いた
出力したいのは
- 2-3桁の掛け算
- あまりのある割り算
- 少数の足し算・引き算
- 分数の足し算・引き算
方針は2つの数について計算して
表示する数式を出力する関数を作る
実際の計算はノートにやってもらって
答え合わせのときに答えを出力させる
イメージはこんな感じ
計算の種類を選んで数字を入力してね 1: 少数のたし算・ひき算 2: 大きな数のかけ算 3: あまりのあるわり算 4: 分数のたし算・ひき算 数値を入力 (1 - 4): 1 1) 94.8 + 84.1 = ? 2) 37.0 + 19.1 = ? 3) 96.1 + 21.9 = ? 終わったらendを入力してね>>end 1) 94.8 + 84.1 = 178.9 2) 37.0 + 19.1 = 56.1 3) 96.1 + 21.9 = 118.0
操作と表示の流れは
- どの計算をするか選んで数字を入力
- 数式の表示
- 手書きで計算が終わったらendを入力
- 答えの表示
となる
問題は分数の表示
アスキーアートみたいに表示はできなくはないけど
できればTeXを使いたい
こんな感じ

調べてみたら
matplotlibを使えば文字をLaTeX表示できるらしい
http://civilyarou.web.fc2.com/Tech_etc/sub_j_latex_test.html
グラフの軸を消してタイル表示させれば
等間隔に数式を並べられる
matplotlibでAxesを真っ白にする(x軸とかy軸なんかを消して非表示にする) - 静かなる名辞
matplotlibのめっちゃまとめ - Qiita
初めてclassを自作した
この本を参考にした
ゼロから作るDeep Learning ―Pythonで学ぶディープラーニングの理論と実装
(Amazonに飛びます)
classには数式を作るメソッドを定義した
数式を作るときに計算の答えも計算してあって
問題の式、答えを含む式の2つを作る
PythonistaではTeXのコマンドが使える程度っぽい
表示はあまりきれいでない
デスクトップでTeX表示する場合は
rc('text', usetex=True)
を使うと表示がきれいになる
実際のコードはこちら
libraryのconsoleはPythonisata3のライブラリなので
デスクトップで実行する場合は削除する
math_exam.py
import console import matplotlib.pyplot as plt from matplotlib.ticker import * from matplotlib import rc import random import numpy as np from math_class import math_equations #rc('text', usetex=True) console.clear() console.set_font('Menlo',20) math = math_equations() x = 3 y = 2 n = x * y print('計算の種類を選んで数字を入力してね') print('1: 少数のたし算・ひき算') print('2: 大きな数のかけ算') print('3: あまりのあるわり算') print('4: 分数のたし算・ひき算') while True: eq_type = input('数値を入力 (1 - 4): ') if eq_type > '0' and eq_type < '5': break ans = [] if eq_type == '1': for j in range(0, int(n/2)): r = np.array(math.generate_decimal(n, 2, 2, 1)) r[0][j], r[1][j] = math.replace_num(r[0][j], r[1][j]) tmp = math.eq_summation(r[0][j], r[1][j]) ans.append(tmp[1]) print(str(j + 1) + ') ' + tmp[0]) if (j + 1) % 5 == 0: print() for j in range(int(n/2), n): r = np.array(math.generate_decimal(n, 2, 2, 1)) r[0][j], r[1][j] = math.replace_num(r[0][j], r[1][j]) tmp = math.eq_subtraction(r[0][j], r[1][j]) ans.append(tmp[1]) print(str(j + 1) + ') ' + tmp[0]) if (j + 1) % 5 == 0: print() elif eq_type == '2': for j in range(n): r = np.array(math.generate_int(n, 2, 2, 1)) r[0][j], r[1][j] = math.replace_num(r[0][j], r[1][j]) tmp = math.eq_multiplication(r[0][j], r[1][j]) ans.append(tmp[1]) print(str(j) + ') ' + tmp[0]) if (j + 1) % 5 == 0: print() elif eq_type == '3': for j in range(n): r = np.array(math.generate_int(n, 1, 2, 1)) r[0][j], r[1][j] = math.replace_num(r[0][j], r[1][j]) r[0][j] = random.randrange(r[1][j],10 * r[1][j]) tmp = math.eq_division(r[0][j], r[1][j]) ans.append(tmp[1]) print(str(j) + ') ' + tmp[0]) if (j + 1) % 5 == 0: print() elif eq_type == '4': fig, axes = plt.subplots(x, y) m = 0 for i in range(x): for j in range(0, int(y/2)): r = np.array(math.generate_int(n, 2, 2, 1)) r[0][j], r[1][j] = math.replace_num(r[0][j], r[1][j]) tmp = math.eq_fraction_sum(r[0][j], r[1][j], r[2][j]) ans.append(tmp[1]) axes[i, j].axis('off') axes[i, j].text(0.0, 0.5, str(m + 1) + ') ' + tmp[0], fontsize = 20) m += 1 for j in range(int(y/2), y): r = np.array(math.generate_int(n, 2, 2, 1)) r[0][j], r[1][j] = math.replace_num(r[0][j], r[1][j]) tmp = math.eq_fraction_sub(r[0][j], r[1][j], r[2][j]) ans.append(tmp[1]) axes[i, j].axis('off') axes[i, j].text(0.0, 0.5, str(m + 1) + ') ' + tmp[0], fontsize = 20) m += 1 plt.show() print() while True: inp=input('終わったらendを入力してね>>') print() if inp == 'end': break if eq_type != '4': for i in range(n): print(str(i + 1) + ') ' + ans[i]) if (i + 1) % 5 == 0: print() else: fig, axes = plt.subplots(x, y) m = 0 for i in range(x): for j in range(y): axes[i, j].axis('off') axes[i, j].text(0.0, 0.5, str(m + 1) + ') ' +ans[m], fontsize = 20) m += 1 plt.show()
math_class.py
import random class math_equations: def __init__(self): pass def eq_summation(self, a, b): re = a + b eq = str(a) + ' + ' + str(b) + ' = ' return eq + '?', eq + str(re) def eq_subtraction(self, a, b): re = a - b eq = str(a) + ' - ' + str(b) + ' = ' return eq + '?', eq + str(re) def eq_multiplication(self, a, b): re = a * b eq = str(a) + ' × ' + str(b) + ' = ' return eq + '?', eq + str(re) def eq_division(self, a, b): re = a // b su = a % b eq = str(a) + ' ÷ ' + str(b) + ' = ' return eq + '?', eq + str(re) + '・・・' + str(su) def eq_fraction_sum(self, a, b, c): re = a + b if a != c and b != c: eq = r'$\frac{' + str(a) + '}{' + str(c) + '} + \\frac{' + str(b) + '}{' + str(c) + '} = ' elif a == c: eq = r'$1 + \frac{' + str(b) + '}{' + str(c) + '} = ' elif b == c: eq = r'$\frac{' + str(a) + '}{' + str(c) + '} + 1 = ' return eq + '?$', eq + '\\frac{' + str(re) + '}{' + str(c) + '}$' def eq_fraction_sub(self, a, b, c): re = a - b if a != c and b != c: eq = r'$\frac{' + str(a) + '}{' + str(c) + '} - \\frac{' + str(b) + '}{' + str(c) + '} = ' elif a == c: eq = r'$1 - \frac{' + str(b) + '}{' + str(c) + '} = ' elif b == c: eq = r'$\frac{' + str(a) + '}{' + str(c) + '} - 1 = ' return eq + '?$', eq + '\\frac{' + str(re) + '}{' + str(c) + '}$' def replace_num(self, a, b): if a < b: tmp = a a = b b = tmp return a, b def generate_int(self, n, dim_x, dim_y, dim_z): a = [] b = [] c = [] for i in range(n): a.append(random.randrange(10 ** (dim_x - 1), 10 ** dim_x)) b.append(random.randrange(10 ** (dim_y - 1), 10 ** dim_y)) c.append(random.randrange(2, 99)) return a, b, c def generate_decimal(self, n, dim_x, dim_y, dim_z): a = [] b = [] c = [] for i in range(n): a.append(round(random.uniform(10 ** (dim_x - 1), 10 ** dim_x), 1)) b.append(round(random.uniform(10 ** (dim_y - 1), 10 ** dim_y), 1)) c.append(round(random.uniform(10 ** (dim_z - 1), 10 ** dim_z), 1)) return a, b, c
実際に触らせてみたら
数字を選ぶところで
画面を触ってた。。。。
さすがデジタルネイティブ
Pythonistaはアプリも作れる
Pythonistaの使い方まとめ - みやびのどっとぴーわい
そのうちタッチ操作できるようにできたらいいね
21 May 2020 追記
この記事のコードを少し書き直した
問題を選ばせるところ
新しく記事を書いたのでリンクを貼る
mecobalamin.hatenablog.com
追記ここまで
30 November 2020 追記
書き直してみた
共通する変数があるときに同じモジュール内に記述する
class MathEquations: def __init__(self, a, b, c, d, equation_type): self.a = a self.b = b self.c = c self.d = d self.equation_type = equation_type def exam_equation(self): kotae = '' amari = '' shiki = '' if self.equation_type == '1': kotae = self.a + self.b shiki = r'$\displaystyle' + str(self.a) + " + " + str(self.b) + ' = $' kotae = r'$' + str(kotae) + '$' elif self.equation_type == '2': kotae = round(self.a * self.b, 1) shiki = r'$\displaystyle' + str(self.a) + '\\times' + str(self.b) + ' = $' kotae = r'$' + str(kotae) + '$' elif self.equation_type == '3': kotae = round(self.a // self.b, 1) amari = self.a % self.b shiki = r'$\displaystyle' + str(self.a) + '\\div' + str(self.b) + ' = $' kotae = r'$' + str(kotae) + '\\cdots' + str(amari) + '$' elif self.equation_type == '4': kotae = self.a + self.b shiki = r'$\displaystyle\frac{' + str(self.a) + '}{' + str(self.c) + '} + \\frac{' + str(self.b) + '}{' + str(self.c) + '} = $' kotae = r'$\displaystyle\frac{' + str(kotae) + '}{' + str(self.c) + '}$' return([shiki, kotae, self.d]) | class GenerateNumbers: def __init__(self, n, x, y, z): self.n = n self.x = x; self.y = y; self.z = z self.a = []; self.b = []; self.c = [] def generate_int(self): for i in range(self.n): self.a.append(random.randrange(10 ** (self.x - 1), 10 ** self.x)) self.b.append(random.randrange(10 ** (self.y - 1), 10 ** self.y)) self.c.append(random.randrange(2, 99)) return(self.a, self.b, self.c) def generate_decimal(self): for i in range(self.n): self.a.append(random.uniform(10 ** (self.x - 1), 10 ** self.x)) self.b.append(random.uniform(10 ** (self.y - 1), 10 ** self.y)) self.c.append(random.uniform(10 ** (self.z - 1), 10 ** self.z)) return(self.a, self.b, self.c)
wslのDockerからWindowsファイルにアクセスする
wslでdockerを使っている
dockerのコンテナからwindowsのにアクセスしたい
そのためにdockerからwindowsのディレクトリにマウントする
環境は
- windows10 home, version 1909
- virtual box, version 5.2.20 r125813 (Qt5.6.2)
- Docker tool box
- ubuntu on wsl
dockerのバージョンは以下の通り
$ docker version Client: Version: 18.09.6 API version: 1.39 Go version: go1.10.8 Git commit: 481bc77 Built: Sat May 4 02:35:57 2019 OS/Arch: linux/amd64 Experimental: false Server: Docker Engine - Community Engine: Version: 18.09.6 API version: 1.39 (minimum version 1.12) Go version: go1.10.8 Git commit: 481bc77 Built: Sat May 4 02:41:08 2019 OS/Arch: linux/amd64 Experimental: false
Ubuntuのバージョンは以下の通り
$ lsb_release -a No LSB modules are available. Distributor ID: Ubuntu Description: Ubuntu 18.04.2 LTS Release: 18.04 Codename: bionic
設定は以下の手順で行った
windows10 homeのwslでdockerを使う手順はこの記事を参照する
mecobalamin.hatenablog.com
1. virtual boxでディレクトリの共有設定
共有したいドライブの共有設定をする
今回はCとEドライブを共有する
Oracle VM VirtualBoxを起動し
[設定] ->[共有フォルダー]とクリックすると以下のウインドウが表示される
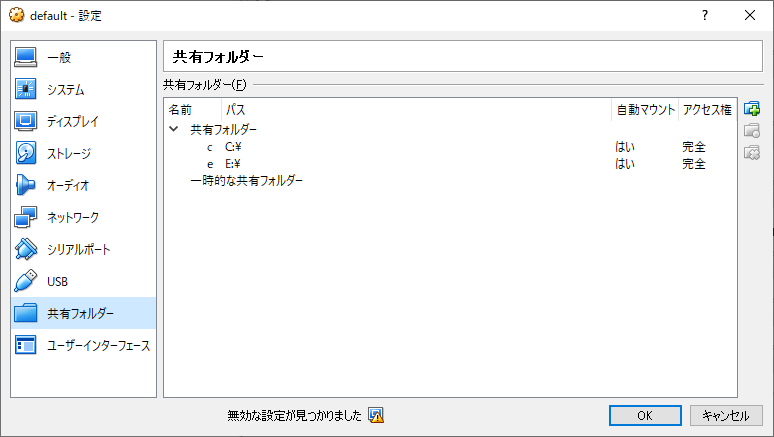
ウインドウ右側にあるボタンをクリックし
共有フォルダーを追加する
例えばcドライブを追加する場合、
フォルダーのパスはC:\
フォルダー名は小文字でc
[自動マウント]と[永続化する]にチェックを入れる
2. マウントディレクトリを変更する
通常、windowsのディレクトリは
wslの/mnt/にマウントされる
これをルート/にマウントするように変更する
変更する理由と変更方法については以下のサイトを参考にした
http://overslept-dev.hatenablog.com/entry/2019/03/11/013929
Docker for WindowsをWSLから使う時のVolumeの扱い方 - Qiita
systemkdのブログ: wsl + Docker for Windows でdocker-compose を動作させる際の Volume設定について
WSLからDocker Desktop for Windowsを使う | kawadeblog
https://inoccu.net/blog/2020/01/14/095703.html
/etc/wsl.confは存在していなかったので作成した
sudo vim /etc/wsl.conf
以下のように書き込んだ
[automount] root = "/"
3. wslの再起動
設定が終わったらwslを再起動して設定を読み込ませる
再起動はwslではなくpower shellで行う
WSL1/WSL2 を再起動する方法 - 備忘録
wslのウインドウを終了させて
power shellで以下のコマンドを実行する
> wslconfig /t Ubuntu
4. dockerの実行
dockerのubuntuを実行する
windowsのeドライブにあるe:\hogeディレクトリを
dockerの/tmp/fugaにマウントする
まず~/.profileでdockerのpathから/mnt/を取り除いて以下のように書き換える
export DOCKER_CERT_PATH=/c/Users/hogehoge/.docker/machine/machines/default
書き換えたら再読み込み
$ source ~/.profile
それからdockerを起動する
docker run --rm -v /e/hoge:/tmp/fuga -it ubuntu /bin/bash
オプションの説明は以下の通り
rmは終了時にコンテナを削除する
vにマウントするディレクトリを指定する
/e/hogeを/tmp/fugaにマウントする
/e/はVirtualBoxで設定した共有フォルダで
大文字・小文字を区別するので注意する
itは標準入出力を使うオプション
ubuntuは使用するイメージ名で起動時に/bin/bash/を使う
実際にマウントできたかどうかを確認する
wslで
echo "from wsl" > /e/hoge/test.txt
としてファイルを作成しdockerで以下のコマンドを実行
less /tmp/fuga/test.txt
ファイルの中身が確認できれば良い
同様にdockerから
echo "from docker" > /tmp/fuga/test.txt
で作ったファイルをwslからアクセスでたらオッケー
ImageNetから画像を一括ダウンロードする
3 November 2020 追記
落としたファイルがESETのウィルススキャンに引っかかた
マルウェアだったっぽい
ファイルのチェックが必要
追記ここまで
機械学習に使う画像を探してみたら
ImageNetに行き着いた
有名なサイトのようだ
image-net.org
starpentagon.net
画像の種類を選んで
画像のURLリストを入手できる
スクレイピングでリストを作成しているらしい
検索かけるとURLを使って画像を
一括ダウンロードするpythonスクリプトが見つかる
ImageNetから画像データをダウンロードする方法 - Murayama blog.
【初心者向け】PythonでURLを指定して画像をダウンロードする - Qiita
PythonでWeb上の画像などのファイルをダウンロード(個別・一括) | note.nkmk.me
画像をダウンロードするスクリプトをpythonで作成した
この方のスクリプトをベースにしている
python3のrequestsを使って画像を保存 - Qiita
これはImageNetからダウンロードしたURLのリスト
http://farm2.static.flickr.com/1255/1408362724_60deb2b753.jpg http://www.autoweek.nl/images/480/e/52e07211aa41ddd948a4fffc8aec126e.jpg http://farm1.static.flickr.com/25/59557472_761b98f3d9.jpg http://farm4.static.flickr.com/3291/2680953450_dfab0392cf.jpg http://farm3.static.flickr.com/2253/2472449713_0c161a43bc.jpg http://farm4.static.flickr.com/3007/2653464907_8372065990.jpg 以下略
URLは1367行
テキストファイル"ImageURL.txt"として保存する
URLはクローラーで集めているらしく
ブラウザで確かめるとリンク切れがある
サーバーそのものにつながらない場合もある
何かしらファイルは在るけど画像でない場合もある
そういったURLをうまく弾くようにする
HTTPエラーはこの方のスクリプトを参考にして弾いた
requestsを使った画像のダウンロード - Qiita
ファイルが画像でない場合も保存しない
【初心者向け】PythonでURLを指定して画像をダウンロードする - Qiita
手間取ったのはサーバーにつながらない場合
サーバーエラーの場合requests.get()は
connection errorを返してくるらしい
クイックスタート — requests-docs-ja 1.0.4 documentation
Developer Interface — requests-docs-ja 1.0.4 documentation
だがConnectionErrorではうまく例外処理ができなくて
"requests.RequestException"を返してきたときに
例外処理をするようにコードを書いた
while True: try: r = requests.get(url, stream=True) except requests.RequestException as e: print('There was an ambiguous exception that occurred while handling your request.') print(e) break
例外を表示させてみると
URLによって様々っぽい
これはその一例
http://www.wewantyou.co.nz/images/cartypes/Stationwagon.jpg
There was an ambiguous exception that occurred while handling your request. HTTPConnectionPool(host='www.wewantyou.co.nz', port=80): Max retries exceeded with url: /images/cartypes/Stationwagon.jpg (Caused by NewConnectionError('<urllib3.connection.HTTPConnection object at 0x7f3e94f55510>: Failed to establish a new connection: [Errno -3] Temporary failure in name resolution'))URLは1367行あるが
実際にダウンロードできた画像は656ファイル
ダウンロードしたファイルは
連番のjpg形式で保存する
zfill()は引数の桁に合わせて0詰めをする
実際に使ったコードはこちら
# -*- coding: utf-8 -*- import requests # Functions # Download images # https://qiita.com/pollenjp/items/0c39c35120cd60575647 def download_img(url, file_name): print(url) while True: try: r = requests.get(url, stream=True) except requests.RequestException as e: print('There was an ambiguous exception that occurred while handling your request.') print(e) break else: if r.status_code != 200: print("You have an HTTP error in this URL.") print("Error Code: " + str(r.status_code)) break elif 'image' not in r.headers["content-type"]: print('This is not Image file.') break else: with open(file_name, 'wb') as f: f.write(r.content) break # read URLs def readFile(FileName): with open(FileName, 'r') as file: # with文で閉じ忘れがない lines = file.readlines() # readlines()で1行毎に読み込み URLs = [] for i in lines: # fileの行数分繰り返す if not i == "\n": URLs.append(i.replace("\n", "")) # 改行コードの削除 return URLs # Main if __name__ == '__main__': # Parameters URL_List = "ImageURL.txt" # Path to files Path_WorkingDirectory = '/Path/to/Working/Directory/' Path_OutputDirectory = Path_WorkingDirectory + 'DownloadImages/' URLs = readFile(URL_List) n = 0 for i in URLs: download_img(i, Path_OutputDirectory + 'Car_' + str(n).zfill(5) + '.jpg') n = n + 1
バイオインフォマティクス技術者認定試験
4 September 2021追記
2021年度の申し込みが始まっている
去年より申込期限と試験日が早くなっている
4 受験申し込み
詳しくは、JSBi認定試験ホームページ
https://www.jsbi.org/activity/nintei/
https://www.jsbi.org/activity/nintei/2021 (今年度 受験情報ページ)
をご覧下さい。
受験申込受付期間は2021年9月1日(水)~2021年12月11日(土)(予定)です。
※直前になると満席の会場が増えますので、早めのお申し込み・ご予約をお勧め致します。
2 試験日・試験地・受験資格・受験料
□ 試験日: 2021年12月1日(水)〜2021年12月14日(火)
□ 試験地: 指定登録テストセンター(受験可能なテストセンター一覧は
認定試験HPにてお知らせいたします)
□ 受験資格 : 受験資格は問いません
□ 受験料 : 5,500円(税込)
追記ここまで
5 December 2020 追記
申し込みが始まっている
(このお知らせは2020年度認定試験開催間近までこの場所に掲載いたします。2020年度実施要領はこのお知らせの下にありますのでスクロールしてご覧下さい)
◆◆本年度CBT試験実施概要および申込みサイトはこちらです。◆◆
※お申込みは2020年12月1日から可能です。
リンク先はこちら
cbt-s.com
追記ここまで
27 September 2020 追記
JSBIのサイト(下記のアドレス)で
2020年度の試験実施要領が公開されている
(3)試験日/受験資格/受験料
□試験日 2021年2月1日(月)〜2021年2月14日(日)(受験期間中1回のみ受験可)
□受験資格 受験資格は問いません。
□受験料 5,500円(不課税)
(6)受験申し込み
受験申込受付は2020年12月1日(火)~2021年2月11日(木)を予定しています。
お申込は専用サイトから手続きを行っていただきます。サイトの準備ができましたらこのページでお知らせいたします。
追記ここまで
23 May 2020 追記
試験の方法が変わるらしい
https://www.jsbi.org/nintei/2020/
● 本年度試験形態について
これまで筆記型試験(マークシート試験)を行っておりましたが、本年度よりCBT試験(Computer Based Testing)に移行いたします。● 本年度試験実施会場、試験期間について
上記の通りCBT試験に移行するため、これまでの都市限定型試験ではなく全国の指定登録会場にて受験が可能となります。(受験会場一覧については後日このページでご案内いたします。)試験受験可能期間も1日限定ではなく1週間~2週間として実施する予定です。受験者の皆様には従来の方式よりも格段に高い自由度で受験日時・会場をお選びいただけます。● 試験実施時期について
新型コロナウイルス感染症拡大に伴う対応といたしまして、例年12月に実施していた試験を2021年1月下旬〜3月上旬に変更することを予定しています。なお実施時期は今後の状況を鑑みて決定いたします。● 本年度の試験内容(キーワード一覧等)について
現在更新作業中です。更新の通知は認定試験トップページのお知らせ一覧にて通知いたします。現時点では以上が決定しておりますが、状況により変更の可能性がありますのでご了承ください。
追記ここまで
2019年度のバイオインフォマティクス技術者検定に合格できた
先月合格通知と成績表が送られてきてた
合格できたが自慢できる成績ではなかった。。。
とはいえ他分野からバイオインフォの分野に移ってみて
勉強・実務をやった成果がどの程度のものか
計るために受験したので
合格できたのは本当に良かったと思う
バイオインフォマティクス技術者認定試験とは
日本バイオインフォマティクス学会が
人材育成の一助として実施している試験である
バイオインフォマティクス技術者認定試験
Japanese Society for Bioinformatics - JSBi :: ホーム
合格したら履歴書に
「JSBi認定バイオインフォマティクス技術者」
(英語名:JSBi Certified Bioinformatics Engineer)
と書いていいらしい
受験対策は参考書を読んで
過去問を解いただけだった
他分野とはいえ生物系での実務経験があったので
若干なめてたがやっぱり厳しかった
なにしろ出題範囲の分野が広い
出題範囲 | Japanese Society for Bioinformatics - JSBi
特に
- 進化・遺伝
- オーミクス
このあたりはお手上げな感じだった
そもそも言葉がわからない
受験対策の参考書として
「バイオインフォマティクス入門」という本を購入
(日本バイオインフォマティクス学会/編、978-4-7664-2251-1)
(Amazonのページに飛びます)
参考書を一通り読んで
ググりながら言葉のチェック
それから過去問を解いた
過去問では同じ問題、似たような問題が
出題されていることがあるので
過去問を解いていたのは良かったが
新しい技術についても出題があり
常にこの分野にアンテナを立ててないと
高得点を取るのは難しそう
平成19年から過去問が公開されていて
毎年平均点と合格基準点が公表されている
過去問は10年分ぐらい解いた
自己採点では合格基準点を超える程度にはできていて
実際の試験でもだいたい同じ程度の得点だった
この数年は毎年同レベルの問題が出ている印象を受けた
試験の結果は合格通知と一緒に送られてくる
各分野ごとの得点と偏差値も知らせてくれる
やっぱり情報科学分野と
バイオインフォマティクス後半の
成績が悪かった
この試験は出題範囲がホント広いと思う
大学生・高校生で合格できる人がいるのは不思議だ
こっちはこれまでになんとなく聞いたことがあったり
実際触ったことがあったりするから
問題解くときにカンも働くけど
学生で合格できるのは本当にすごいと思う
合格者には認定シールも送られてくる
とりあえずPCに貼った
PCにシールを貼ると剥がすとき大変らしい
パソコンに貼りまくったステッカーをはがしたら画面がおかしくなった - phaの日記
OpenCVを使って物体認識その5、pythonスクリプトで物体認識
続きです
mecobalamin.hatenablog.com
まず認識結果から



これだけだとそれなりに
うまくできてそうだけど
実際は認識できてないのが多い
何故か手前じゃなくて奥の猫とか

下を向いていたり、足だけとか

正面向いてるのに全く認識できてないとか

なんでだろ
正面顔のデータが少ないか
ここまでは正解データをテストに使った
正解に使っていない画像を認識させた結果がこれ


顔以外のところを認識してる
traincascadeのパラメーター変えると
また結果が変わるんだけど
正解データが足りないだけなのかも
とりあえずここまでは動いた
あとはパラメータ調整と正解画像を増やせるか試すとして
一旦まとめは終了
使ったpythonのコードも残す
この方のコードをベースに追記して使わせてもらった
qiita.com
追加した部分とコードについて理解した範囲でメモ
opencv_traincascadeで生成したcascade.xmlの
ディレクトリをmodelに指定している
cats_classificationは認識に使う画像の在るディレクトリ
cats_outputは認識後の画像を保存するディレクトリ
指定したディレクトリのファイル名を取得して
それらについて猫の顔を認識させている
画像はグレースケールにしてから認識
ここのパラメータでも認識結果が変わる
Cascade.detectMultiScale(gray, 1.3, 3)
認識されたら赤い矩形を上書きして保存する
このときFile_Dateで指定した日付をファイル名に追加する
# import library import cv2 import numpy as np from glob import glob from os.path import relpath # Parameters File_Date = "20xx" # Path to files Path_Classifier = '/path/to/file/model' Path_Images = '/path/to/file/cats_classification' Path_Output = '/path/to/file/cats_output' # 学習器(cascade.xml)の指定 Cascade = cv2.CascadeClassifier(Path_Classifier + "/cascade.xml") # ファイル名の取得 List_Images = glob(Path_Images + "/*.jpg") List_Names = [] for i in List_Images: List_Names.append(relpath(i, Path_Images)) # 予測対象の画像の指定 for i in List_Names: print(i) img = cv2.imread(Path_Images + "/" + i, cv2.IMREAD_COLOR) gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY) point = Cascade.detectMultiScale(gray, 1.3, 3) print(len(point)) if len(point) > 0: for rect in point: cv2.rectangle(img, tuple(rect[0:2]), tuple(rect[0:2]+rect[2:4]), (0, 0,255), thickness=2) else: print("no detect") cv2.imwrite(Path_Output + "/" + "Detected_" + File_Date + "_" + i, img)
画像Path_Outputで指定されたディレクトリに保存される
vimのコピーについてメモ
vimでクリップボードにコピーするときは
ビジュアルモードに入って
"+y
いつも忘れる
OpenCVを使って物体認識その4、createsamplesとtraincascade
続きです
mecobalamin.hatenablog.com
生成した正解データと不正解データを使って
学習させたcascade.xmlを生成する
正解データのモンタージュ

不正解データのモンタージュ

逆さまとはいえ猫の顔の一部や全体が入っているので
うまくいかないかもだがとりあえず使ってみる
これらを使って学習させる
手順は
ImageJで正解・不正解データを生成したときに
それぞれpositive.txtとnegative.txtという
2つのテキストファイルも生成されている
これには生成された画像ファイルのパスが記録されているが
windows側で生成されているので
wslで使えるようにパスの書き換えと
改行コードの変更が必要
仮にファイルがEドライブに保存されているとすると
wslでは/mnt/e/にマウントされているので
E:を/mnt/e/に書き換える
次にnkfコマンドを使って改行コードを書き換える
【 nkf 】コマンド――文字コードと改行コードを変換する:Linux基本コマンドTips(51) - @IT
以下スクリプトを使っている
cat positive.txt | sed -e 's/E:/\/mnt\/e/' > modified_positive.txt cat modified_positive.txt | sed -e 's/\\/\//g' > tmp.txt nkf -Lu tmp.txt > modified_positive.txt cat negative.txt | sed -e 's/E:/\/mnt\/e/' > modified_negative.txt cat modified_negative.txt | sed -e 's/\\/\//g' > tmp.txt nkf -Lu tmp.txt > modified_negative.txt
ファイルの書き換えが済んだら
opencv_createsamplesを実行する
opencv_createsamplesとopencv_traincascadeの
パラメータを翻訳してくれてる
とても参考になった
OpenCV 備忘録: OpenCVのカスケード分類器の学習の章を訳してみた
opencv_createsamplesの実行だが
modifiled_positive.txtのあるディレクトリで
実行するのが良さげ
絶対パスを指定すると
うまく動いていない気がする
numは正解データの数、wとhは生成する画像のサイズを指定する
正解データよりは小さくする必要がある
あまり大きくするとtraincascadeの実行時に時間がかかる
実行後は-vecで指定したファイルが生成される
$ opencv_createsamples -info modified_positive.txt -vec hogehoge.vec -num 121 -w 64 -h 64
opencv_traincascadeの実行ではopencv_createsamplesで
生成したファイルを使ってcascade.xmlを作る
これは絶対パスを指定してちゃんと動いている気がする
dataは生成するcascade.xmlファイルを保存するディレクトリを指定する
コマンド実行前にディレクトリを作っておく
vecはopencv_createsamplesで生成したファイルを指定する
bgは不正解データのパスを記録したファイルを指定する
numPosとnumNegは正解データと不正解データの数だが
numPosは実際の数よりも少なくする
なぜなら正解データが足りないというエラーが出ることがあるから
wとhはcreatesamplesで使ったのと同じ値を使う
precalcValBufSizeとprecalcdxBufSizeは使用するメモリサイズっぽいが
topコマンドやwindowsのリソースモニタでは
メモリをもっと使っているようなので
実際何を指定しているかまだよくわからない
topコマンド
【 top 】コマンド――実行中のプロセスをリアルタイムで表示する:Linux基本コマンドTips(123) - @IT
numTreadsはCPUのスレッド数なので使うPCに依存する
numStageは計算をする回数で指定した回数よりも早く終る場合もある
cascade.xmlができていればいいらしい
今回は8を使っているがそれはここまでならエラーが出ないから
大きくすると正解画像が足り無いエラーが出る
maxFalseAlarmRateとminHitRateもよくわかってないが
小さくすると条件が厳しいのか認識が良くなった気がする
ちなみにデフォルトは0.5と0.995
$ opencv_traincascade -data /path/to/file/model -vec /path/to/file/hogehoge.vec -bg /path/to/file/modified_negative.txt -numPos 60 -numNeg 121 -w 64 -h 64 -precalcValBufSize 2048 -precalcIdxBufSize 2048 -numThreads 4 -numStages 8 -maxFalseAlarmRate 0.1 -minHitRate 0.97
実行結果の最後
0からスタートし7-stageで終わっている
===== TRAINING 7-stage ===== <BEGIN POS count : consumed 60 : 74 NEG count : acceptanceRatio 121 : 0.000325694 Precalculation time: 29 +----+---------+---------+ | N | HR | FA | +----+---------+---------+ | 1| 1| 1| +----+---------+---------+ | 2| 1| 1| +----+---------+---------+ | 3| 1| 0.735537| +----+---------+---------+ | 4| 1| 0.85124| +----+---------+---------+ | 5| 1| 0.322314| +----+---------+---------+ | 6| 0.983333| 0.140496| +----+---------+---------+ | 7| 1| 0.190083| +----+---------+---------+ | 8| 1|0.0826446| +----+---------+---------+ END> Training until now has taken 0 days 0 hours 40 minutes 48 seconds.
このときの計算時間は40分ぐらい
ちなみにtraincascade実行中のtopコマンドの表示
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND 835 user 20 0 23.197g 0.018t 300364 R 100.0 77.5 341:12.99 opencv_traincas
続きます